数据结构
线性结构
数组、单链表、双链表
- 数组:连续,随机访问速度快;Collection集合中提供了ArrayList和Vector
- ArrayList:线程不安全,不够用时扩展0.5倍,Collections.synchronizedList<List
list>实现线程安全 - (弃用)Vector:线程安全,不够用时扩展1倍
- ArrayList:线程不安全,不够用时扩展0.5倍,Collections.synchronizedList<List
- 单链表:节点的链接方向是单向的;相对于数组来说,单链表的的随机访问速度较慢,但是单链表删除/添加数据的效率很高。
- 双链表:双链表的优点是可以从头部或尾部访问,也可以直接访问中间的元素。此外,由于有指向前一个节点的指针,因此可以从尾部或中间删除元素,而不需要遍历整个链表,缺点是每个节点需要更多的存储空间(两个指针)
栈
- LIFO:后进先出
- 操作只能从栈顶进行操作
- push、pop、peek:进栈、出栈、返回栈顶元素
- 应用场景:函数调用和递归;表达式求值、括号匹配;回溯算法DFS深度优先搜索
队列
- FIFO:先进先出
- 只允许在队首进行删除、队尾进行插入操作
- 应用场景:任务调度;缓冲区;优先级队列;广度优先搜索BFS
树形结构
遍历
先序、中序、后序,取决于何时读取根节点
二叉查找树
时间复杂度O(logN),极端情况下会变成线性结构O(N)
- 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树;
- 没有键值相等的节点(no duplicate nodes);
AVL树
因为规定了左右子树高度差,所以不会变成线性链表,时间复杂度O(logN),由于需要保持自身平衡,需要频繁旋转,多次磁盘IO
- 任何节点的两个子树最大高度差为1
B树
自然平衡树。内部通过分裂机制,保持数据有序。单节点可以保存2~4个信息,节点内有序,节点间间隔,减少磁盘IO次数。
适合单点查询的场景,如MongoDB。
不适合的场景:所有节点都放在磁盘上,读写性能差;范围查时,如果范围跨节点会出现节点间反复横跳情况。
B+树
B+树为了解决B树存在的缺陷而设计。相比B树,B+树非叶子节点仅保留数据间相对关系(索引)
,真实信息均包含在叶子节点中,相对关系信息(非叶子节点)就可以放在内存中,真实信息放在磁盘中。
MySql的存储引擎InnoDB用的就是B+树。
B+树信息存在磁盘中,且非顺序写入,所以查询性能很高,但是写入性能偏低,即B+树结构不适合频繁大数据量的写入,核心原因是因为非顺序写入。
B*树
B* 树是对B+树的再一次改进,在B+树构建过程中,节点的合并拆分比较费时,所以B*树就是为了减少构建过程中节点合并和拆分的次数,从而提升树的数据插入、删除性能。
与B+树的区别:
- 关键字个数限制问题,B+树初始化的关键字初始化个数是cei(m/2),b树的初始化个数为(cei(2/3m))
- B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来
伸展树
- 当某个节点被访问时,会旋转使该节点成为根,下次访问该节点时,能迅速访问到
红黑树
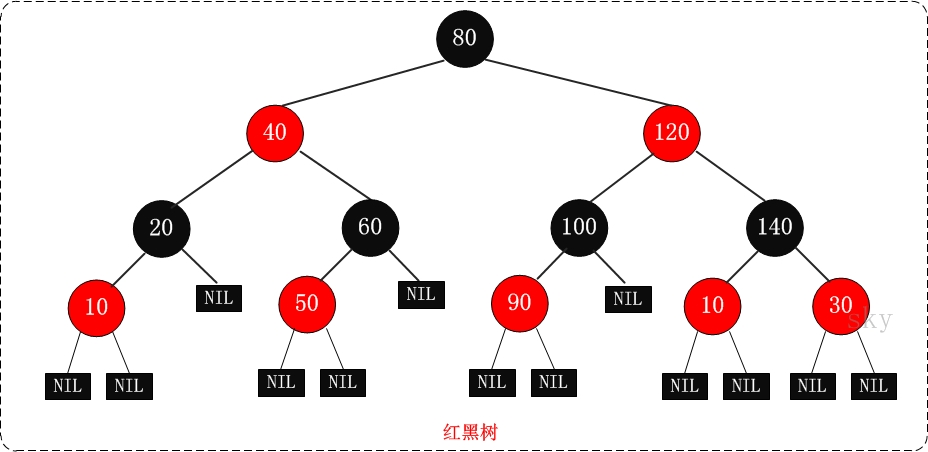
- 每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
哈夫曼树
哈夫曼又称最优二叉树, 是一种带权路径长度最短的二叉树。
应用场景主要:数据压缩;编码;通信;图像处理
前缀树
trie tree,又称字典树,用于前缀匹配、字符串检索、词频统计、字符串排序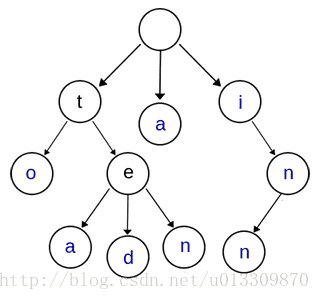
基本性质:
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符;
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符互不相同;
- 从第一字符开始有连续重复的字符只占用一个节点,比如上面的to,和ten,中重复的单词t只占用了一个节点。
常见的问题:
HashMap为什么使用红黑树不使用B树
jdk1.8之前使用链表散列实现,
jdk1.8之后当链表长度超过阈值(8)时会进行检测,如果长度小于64会进行数组扩容,大于64转化为红黑树
TreeMap、TreeSet以及jdk1.8之后的Hashmap都是用了红黑树,为了解决二叉查找树的缺陷——在某些情况下二叉查找树会退化成一个线性结构HashMap为什么使用红黑树,不使用B树
效率和复杂度,红黑树在插入、删除、查找等操作上平衡性更好,且节点数比B树小,占用内存更少,适合存储在内存中的数据结构
3.
图
由顶点的又穷非空集合和顶点之间的边的集合组成
图的存储结构
- 邻接矩阵表示法
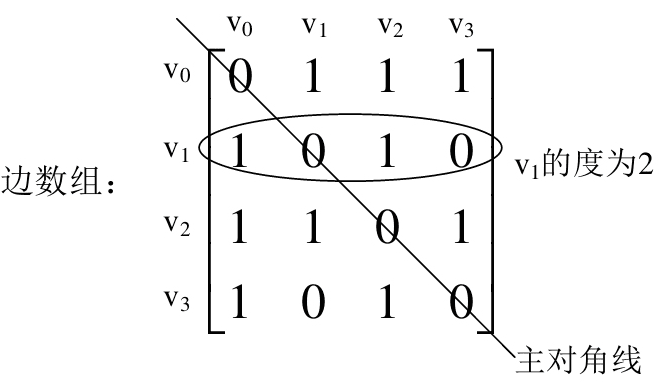
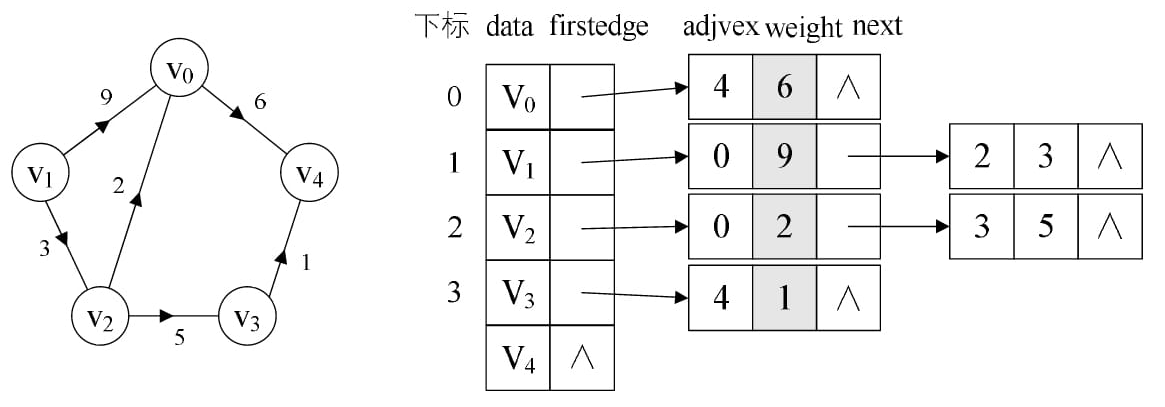
当图为稀疏图时,会造成极大空间浪费 - 邻接表表示法
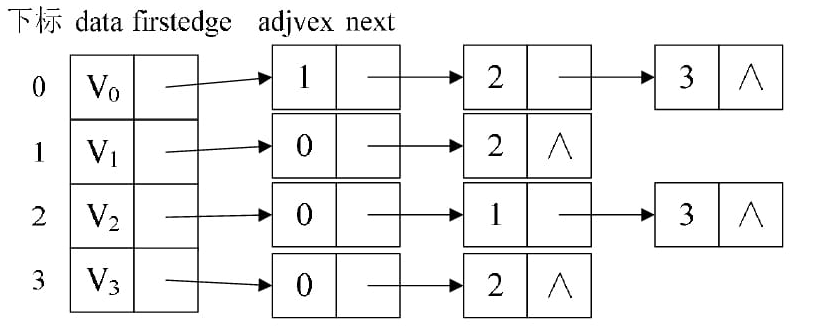
- 带权图
遍历
- 深度优先
- 广度优先
最小生成树
- 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图。
- 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连通图。
- 连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。
- 生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
- 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
最小生成树算法
- Kruskal算法:大量对边操作,适用于稀疏图
- Prim算法:适用于稠密图,但对优化的prim更适用于系数图,时间复杂度取决于边的数量
最短路径
查找图中两点之间最短路径(权值最小)
Dijkstra算法和Floyd算法都是用于求解单源最短路径问题的算法,但是它们在处理有向图时存在一些区别。
Dijkstra算法是一种贪心算法,它从源点开始,逐步扩展已知的最短路径集合,直到所有顶点都被包含在内。Dijkstra算法的基本思想是:从源点开始,逐步扩展已知的最短路径集合,直到所有顶点都被包含在内。Dijkstra算法在处理有向图时,会根据边的权值来更新最短路径。
Dijkstra算法和Floyd算法的优劣势如下:
Dijkstra算法的优势:
- Dijkstra算法可以处理有负权边的有向图,只要图中不存在负权环。
- Dijkstra算法的时间复杂度较低,为O(V^2)或O(E log V),其中V是顶点数,E是边数。
Dijkstra算法的劣势:
- Dijkstra算法需要额外的空间来存储最短路径集合,空间复杂度为O(V)。
- Dijkstra算法在处理有向图时,如果图中存在负权边,可能会导致算法无法找到最短路径。
Floyd算法是一种动态规划算法,它通过迭代地更新所有顶点对之间的最短路径来求解单源最短路径问题。Floyd算法的基本思想是:通过迭代地更新所有顶点对之间的最短路径,来求解单源最短路径问题。Floyd算法在处理有向图时,会根据边的权值来更新最短路径。
Floyd算法的优势:
- Floyd算法可以处理有负权边的有向图,只要图中不存在负权环。
- Floyd算法不需要额外的空间来存储最短路径集合,空间复杂度为O(V^2)。
Floyd算法的劣势:
- Floyd算法的时间复杂度较高,为O(V^3),其中V是顶点数。
- Floyd算法在处理有向图时,如果图中存在负权环,可能会导致算法无法找到最短路径。
拓扑排序
主要用来解决有向图中的依赖解析问题
当且仅当一个有向无环图,才能得到对应该图的拓扑排序
入度、出度:指节点被指向和指向其他节点的边的数目
AOE&关键路径
AOE&AOV,常用于工程管理、流程控制
- AOV:顶点表示活动的网,只描述活动之间制约关系
- AOE:用边表示活动的网,权值表示持续时间
算法
排序
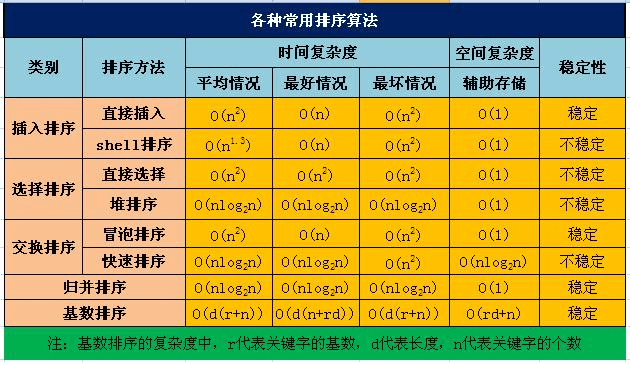
常见算法
冒泡排序
每次遍历比较相邻数大小,如果后者比前者小则交换位置,重复操作,直到整个数列有序
/** * bubbleSort * @param aList */ public static void bubbleSort(int[] aList) { int tmp; System.out.println("begin"); for (int i = 0; i < aList.length; i++) { System.out.print(aList[i]); } for (int i = 0; i < aList.length; i++) { for (int j = i; j < aList.length; j++) { if (aList[i] > aList[j]) { tmp = aList[i]; aList[i] = aList[j]; aList[j] = tmp; } } } System.out.println("\nend"); for (int i = 0; i < aList.length; i++) { System.out.print(aList[i]); } }快速排序
分治思想,随机选择基准数,通过排序分隔为两部分,一部分比基准小、另一部分比基准大,递归快排/** * quickSort * @param aList * @param l * @param r */ public static void quickSort(int[] aList, int l, int r) { if (l < r) { int i, j, x; i = l; j = r; x = aList[i]; while (i < j) { while (i < j && aList[j] > x) j--; // 从右向左找第一个小于x的数 if (i < j) aList[i++] = aList[j]; while (i < j && aList[i] < x) i++; // 从左向右找第一个大于x的数 if (i < j) aList[j--] = aList[i]; } aList[i] = x; quickSort(aList, l, i - 1); /* 递归调用 */ quickSort(aList, i + 1, r); /* 递归调用 */ } }插入排序
希尔排序
分组插入方法选择排序
选择排序
堆排序
归并排序
桶排序
基数排序



